當紐約證券交易所的開盤鐘聲響起,每秒鐘有超過一百萬筆訂單湧入系統。在這個以微秒計算勝負的戰場上,一個 10 微秒的延遲可能意味著數百萬美元的損失。更令人驚嘆的是,現代金融交易系統不僅要在極限速度下運作,還必須保證 99.999% 的可用性——這意味著一年的停機時間不能超過 5.26 分鐘。
如何在毫秒之間處理億萬決策,同時確保每一筆交易的準確性和合規性?這就是今天我們要探討的終極挑戰。金融交易系統代表了現代分散式系統的巔峰之作。它不只是一個技術系統,更是全球經濟運轉的心臟。
今天,我們將深入剖析如何設計一個能夠處理每秒百萬級交易、延遲低於微秒級別,並且滿足全球監管要求的金融交易平台。
想像一家中型證券交易所正準備建構新一代電子交易平台。這個平台需要服務全球的金融機構、專業交易員和個人投資者,處理包括股票、期貨、選擇權等多種金融商品的交易。每天早上九點半開盤的瞬間,數十萬個交易員同時下單,系統必須在微秒內完成價格撮合、風險檢查、交易確認等一系列複雜操作。
這個系統不僅是一個技術平台,更是維護市場公平、透明、有序運作的關鍵基礎設施。任何技術故障都可能引發市場恐慌,造成難以估量的經濟損失。
訂單管理系統
撮合引擎
清算結算系統
風險管理模組
市場數據服務
監管報告功能
效能要求
可用性要求
擴展性要求
安全性要求
成本限制
金融交易系統面臨三個核心技術挑戰,每一個都直接影響系統的成敗。
技術挑戰 1:極致低延遲的追求
在高頻交易的世界裡,時間就是金錢。當兩個交易員幾乎同時下單購買同一支股票時,即使只有 1 微秒的差異,也會決定誰能成交、誰會錯失機會。更關鍵的是,許多高頻交易策略依賴於在極短時間內捕捉市場微小的價格差異,每微秒的延遲都可能導致策略失效,造成巨大損失。
技術挑戰 2:強一致性與高可用性的矛盾
金融交易不允許任何數據不一致。想像一下,如果同一筆資金被重複使用,或者交易記錄出現遺失,將會引發嚴重的信任危機。然而,要在分散式系統中保證強一致性,通常需要犧牲可用性。如何在 CAP 理論的限制下,找到適合金融場景的平衡點,是架構設計的核心難題。
技術挑戰 3:全球監管合規的複雜性
金融市場受到嚴格監管,不同國家和地區有著各自的法規要求。歐盟的 MiFID II 要求記錄每筆交易的 203 個欄位,美國的 Reg NMS 規定了最佳執行義務,亞洲各國也有自己的監管框架。系統必須在滿足所有這些要求的同時,還要保持高效運作,這需要在架構層面就做好規劃。
| 維度 | 單體架構 | 微服務架構 | 事件驅動架構 |
|---|---|---|---|
| 核心特點 | 所有功能集成在單一應用中,採用進程內函數調用 | 功能拆分為獨立服務,通過網路通訊協作 | 基於事件流的鬆耦合設計,異步處理為主 |
| 優勢 | 開發簡單直觀、延遲最低(無網路開銷)、事務處理簡單 | 獨立擴展能力強、故障隔離、技術棧靈活 | 高度解耦、易於擴展、自然支援事件溯源 |
| 劣勢 | 擴展困難、單點故障風險、技術債累積快 | 網路延遲增加、分散式事務複雜、運維成本高 | 最終一致性、除錯困難、延遲不可預測 |
| 適用場景 | 日交易量 < 100萬筆的小型交易所 | 大型綜合交易平台、多資產類別交易 | 跨市場交易系統、事件驅動型業務 |
| 複雜度 | 低:單一程式碼庫、簡單部署 | 高:服務治理、分散式追蹤、複雜運維 | 中高:事件流管理、狀態重建 |
| 成本 | 低:硬體需求少、運維簡單 | 高:更多伺服器、專業運維團隊 | 中:基礎設施投資、但長期維護成本較低 |
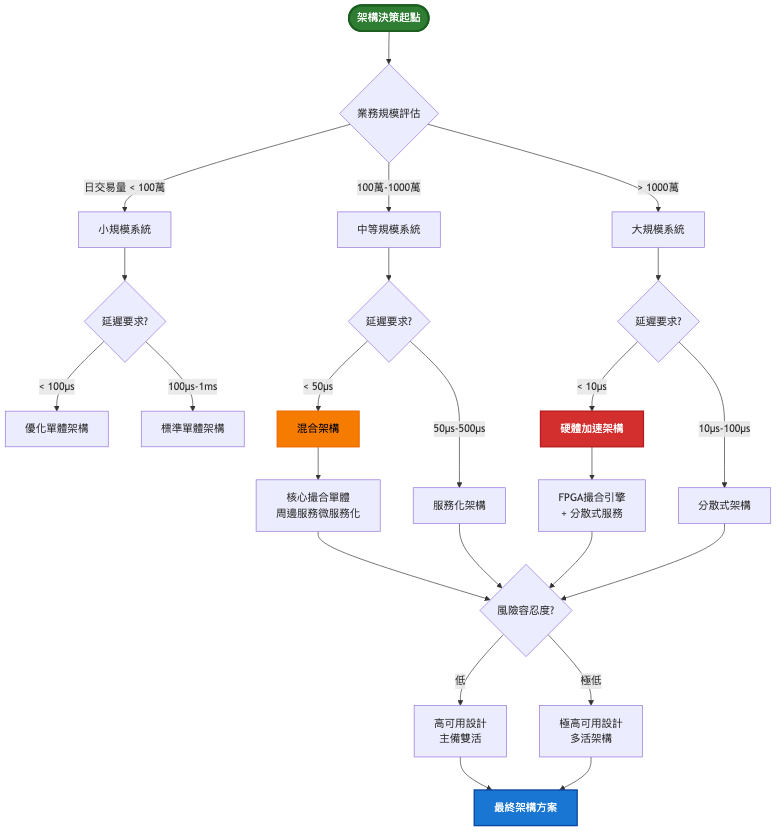
架構重點:
在 MVP 階段,我們的首要目標是快速上線並驗證業務模式。此時選擇單體架構是最明智的決定,因為它能夠提供最低的開發複雜度和最佳的初期效能。核心系統採用 Java 開發,使用 Spring Boot 框架快速構建。撮合引擎採用記憶體內處理,確保訂單匹配的低延遲。PostgreSQL 作為主資料庫,儲存所有交易記錄和帳戶資訊。Redis 提供高速快取,加速熱點數據的存取。
系統架構圖:
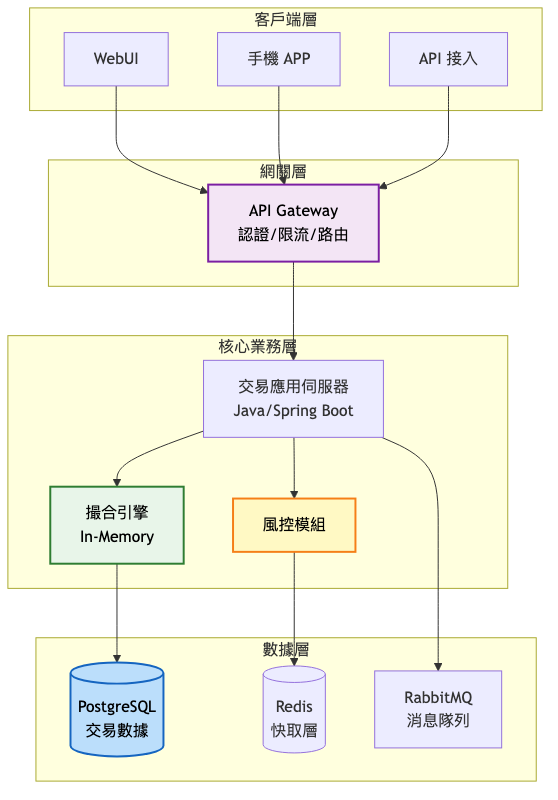
關鍵架構變更:
這個階段的設計重點在於簡單可靠。撮合引擎採用價格優先、時間優先的經典演算法,使用 TreeMap 儲存買賣盤,確保價格排序的效率。所有訂單處理都在單一進程內完成,避免了網路延遲。風控模組採用規則引擎,支援簡單的限額檢查和部位監控。
預期效能提升對比表:
| 指標 | 傳統方案 | MVP架構 | 改善幅度 |
|---|---|---|---|
| 訂單處理延遲 | 10ms | 500μs | 20x |
| 日處理能力 | 10萬筆 | 100萬筆 | 10x |
| 開發週期 | 12個月 | 3個月 | 4x |
| 初期投資 | 1000萬美元 | 200萬美元 | 5x |
架構重點:
隨著業務量的快速增長,原有的單體架構開始顯現瓶頸。這個階段的改造重點是在保持核心撮合引擎高效能的同時,將周邊系統服務化。我們引入了 LMAX Disruptor 模式重構撮合引擎,實現無鎖化處理。同時採用 Kafka 作為事件串流平台,實現系統間的解耦。最重要的是,我們開始引入 FPGA 硬體加速,將關鍵的風控檢查下沉到硬體層。
系統架構圖:
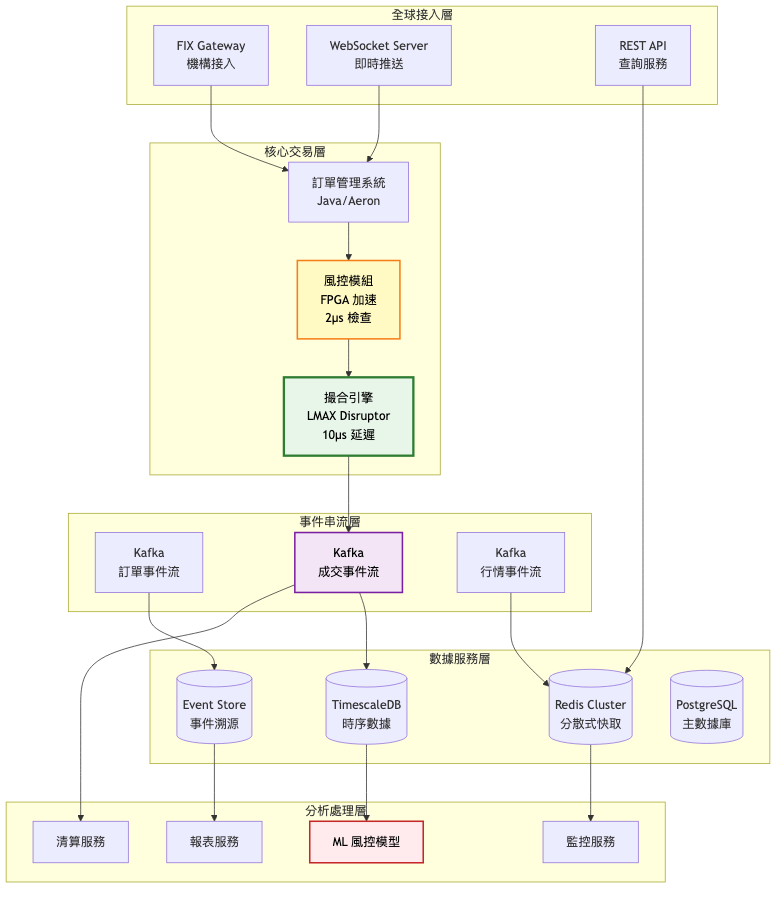
關鍵架構變更:
高效能撮合引擎升級
FPGA 風控加速
事件驅動架構引入
演進決策指南表:
| 觸發條件 | 採取行動 | 預期效果 |
|---|---|---|
| 日交易量 > 100萬 | 撮合引擎記憶體優化 | 延遲降低 50% |
| P99 延遲 > 100μs | 引入 FPGA 加速 | 延遲降至 10μs |
| 審計查詢 > 1000次/天 | 部署事件溯源 | 查詢速度提升 10x |
| 風控規則 > 100條 | ML 模型替代規則 | 準確率提升 30% |
架構重點:
當系統發展到這個規模,我們需要的不僅是技術優化,更是一個全球化的分散式架構。這個階段引入了邊緣運算,在全球主要金融中心部署邊緣節點,就近處理交易請求。核心撮合引擎採用分片架構,按照資產類別進行水平擴展。同時,我們建立了完整的 AI 驅動的智慧運維體系,實現預測性維護和自動故障恢復。
總覽架構圖:
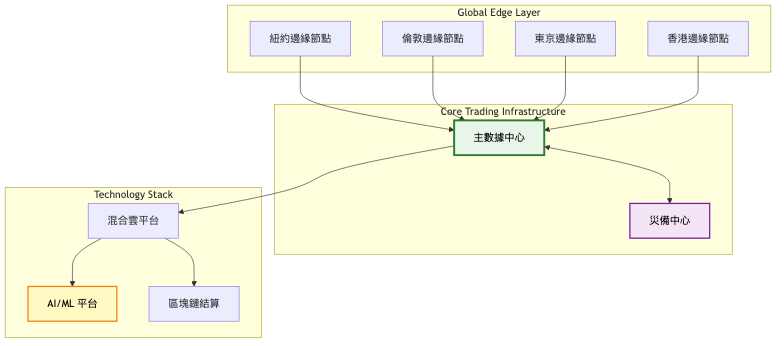
核心交易系統詳細圖:
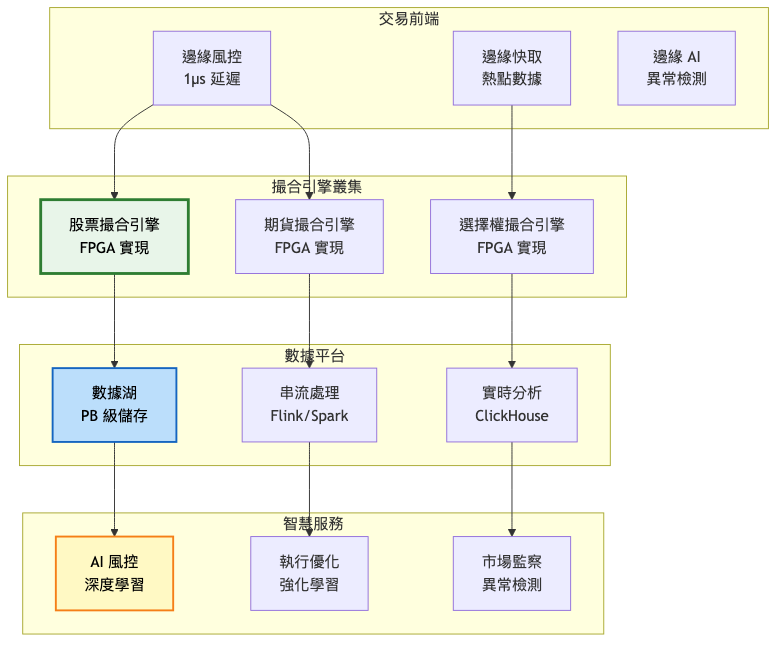
架構演進對比表格:
| 架構特性 | MVP階段 | 成長期 | 規模化 |
|---|---|---|---|
| 架構模式 | 單體應用 | 混合架構 | 微服務+邊緣 |
| 撮合引擎 | Java 記憶體處理 | LMAX Disruptor | FPGA 硬體 |
| 資料庫 | PostgreSQL 單機 | 主從複製+分片 | 分散式數據湖 |
| 快取策略 | Redis 單機 | Redis Cluster | 邊緣快取+CDN |
| 部署方式 | 單機部署 | 多機叢集 | 全球多活 |
| 團隊規模 | 5-10人 | 30-50人 | 100+人 |
| 用戶規模 | < 1萬 | 10萬-100萬 | 1000萬+ |
| 日交易量 | < 100萬 | 100萬-1000萬 | > 1000萬 |
| 系統延遲 | 500μs | 10-50μs | < 10μs |
在金融交易系統中,每個技術選擇都會深刻影響系統的效能、可靠性和可維護性。讓我們深入分析各個關鍵組件的選型考量。
撮合引擎技術選型:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Java + Disruptor | 生態成熟、開發效率高、社群支援完善、易於維護 | GC 暫停影響延遲、記憶體開銷大、效能上限受限 | 中型交易所、商品期貨市場 |
| C++ + Lock-free | 零 GC、精確記憶體控制、CPU 快取優化、延遲可預測 | 開發週期長、除錯困難、人才稀缺、維護成本高 | 大型股票交易所、高頻交易平台 |
| FPGA 硬體實現 | 奈秒級延遲、確定性延遲、並行處理、功耗低 | 開發極其困難、靈活性差、升級複雜、成本極高 | 頂級交易所核心系統、超高頻交易 |
| Rust + Tokio | 記憶體安全、無 GC、高並發、現代語言特性 | 生態較新、學習曲線陡峭、人才更稀缺 | 新一代交易系統、加密貨幣交易所 |
訊息中介層選型:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| Apache Kafka | 高吞吐(百萬/秒)、持久化、生態完整、容錯性強 | 延遲較高(毫秒級)、運維複雜、資源消耗大 | 事件串流、交易日誌、審計追蹤 |
| Aeron | 極低延遲(微秒級)、高效能、可靠UDP、零拷貝 | 功能單一、無持久化、社群較小、文件少 | 撮合引擎內部通訊、行情推送 |
| NATS | 輕量級、易部署、支援多種模式、雲原生 | 持久化較弱、功能相對簡單、大規模部署經驗少 | 微服務通訊、即時通知 |
| RabbitMQ | 功能豐富、靈活路由、管理界面友好、AMQP標準 | 效能受限、Erlang 運維難、叢集擴展複雜 | 任務隊列、工作流程orchestration |
資料儲存層選型:
| 技術選項 | 優勢 | 劣勢 | 適用場景 |
|---|---|---|---|
| PostgreSQL | ACID 保證、功能完整、擴展豐富、社群活躍 | 寫入效能受限、垂直擴展為主、大規模複製延遲 | 帳戶資訊、交易記錄、參考數據 |
| TimescaleDB | 時序優化、自動分區、壓縮率高、PostgreSQL 相容 | 相對較新、特定場景優化、license 限制 | 市場行情、歷史數據、效能指標 |
| Redis | 記憶體速度、資料結構豐富、Lua 腳本、發布訂閱 | 持久化較弱、記憶體成本高、大數據集受限 | 即時快取、Session、即時排行 |
| Cassandra | 線性擴展、多數據中心、最終一致性、高可用 | 一致性較弱、查詢受限、運維複雜、JVM 調優難 | 訂單歷史、日誌儲存、時間序列 |
| ClickHouse | 列式儲存、極速分析、壓縮率極高、SQL 支援 | 非事務性、更新成本高、叢集管理複雜 | 實時分析、報表查詢、市場分析 |
成功的技術演進需要在穩定性和創新之間找到平衡。金融系統的技術演進必須遵循以下原則:
首先是漸進式演進原則。不要試圖一次性重寫整個系統,而是識別瓶頸,逐步優化。例如,可以先將撮合引擎從 Java 遷移到 C++,保持其他組件不變。當這部分穩定後,再考慮引入 FPGA 加速。
其次是雙軌並行策略。在引入新技術時,保持舊系統繼續運行。新系統可以先處理一小部分流量,逐步增加比例。這種金絲雀發布的方式可以及時發現問題,降低風險。
技術債務管理也至關重要。定期評估技術債務,分配 20% 的開發資源用於償還技術債。建立技術債務登記冊,追蹤每項債務的成本和影響。當債務利息(維護成本)超過本金(重構成本)時,果斷進行重構。
最後是前瞻性技術儲備。雖然不能過早採用不成熟的技術,但要保持對新技術的關注。建立創新實驗室,小規模試驗新技術。當技術成熟度達到要求時,能夠快速應用。
過早優化陷阱
忽視故障演練
監管合規後置
單點故障忽視
案例:NASDAQ 的雲端轉型之路
參考文章
初期(2016-2019):傳統架構時期
成長期(2019-2023):混合雲探索
近期狀態(2024-2025):全面雲原生
金融交易系統中,幾個關鍵的設計模式反覆出現,理解這些模式對於構建高效能系統至關重要。
LMAX Disruptor 模式:是高效能訊息傳遞的革命性設計。它通過環形緩衝區避免了鎖競爭,使用記憶體屏障確保可見性,實現了每秒數千萬訊息的處理能力。在撮合引擎中,訂單通過 Disruptor 傳遞,多個消費者(風控、撮合、審計)並行處理,大幅提升了系統吞吐量。實施時需要特別注意記憶體屏障的正確使用,避免 CPU 快取行偽共享問題。
Event Sourcing 模式:將所有狀態變更儲存為不可變事件序列。每個訂單、每次撮合、每個價格變動都是一個事件。系統狀態通過重播事件序列來重建。這不僅提供了完整的審計追蹤,還支援時間旅行除錯,可以重現任何歷史時刻的系統狀態。結合 CQRS 模式,將命令處理和查詢處理分離,可以針對不同的讀取場景優化資料模型。
Circuit Breaker 模式:保護系統免受連鎖故障影響。當下游服務出現問題時,斷路器開啟,快速失敗,避免請求堆積。這在金融系統中特別重要,因為一個服務的故障可能快速擴散,影響整個交易系統。
基於多年的實戰經驗,以下最佳實踐被證明是有效的:
關鍵路徑優化:識別訂單處理的關鍵路徑,從網路接收到撮合完成的每一步都要優化。使用火焰圖分析 CPU 使用,消除熱點程式碼。避免在關鍵路徑上進行 I/O 操作、記憶體分配或鎖等待。
冪等性設計:所有交易操作必須是冪等的,支援安全重試。使用唯一交易 ID,重複請求返回相同結果。這對於處理網路超時、重複提交等問題至關重要。
優雅降級策略:定義清晰的服務降級策略。當系統負載過高時,可以暫停非核心功能如複雜查詢、歷史數據分析,優先保證交易撮合。設定多級降級方案,根據系統壓力自動切換。
灰度發布機制:新功能和系統升級採用灰度發布。先在小範圍用戶測試,逐步擴大範圍。使用功能開關控制新功能的啟用,出現問題可以快速回滾。建立完善的監控指標,及時發現問題。
金融交易系統的監控需要覆蓋技術和業務兩個維度,建立立體化的監控體系。
技術指標:
業務指標:
金融系統的維護不僅要保證系統運行,更要持續優化和改進。
自動化運維體系構建全方位的自動化能力。自動化測試覆蓋率達到 90% 以上,包括單元測試、整合測試、效能測試和壓力測試。建立 CI/CD 流水線,程式碼提交後自動構建、測試、部署到測試環境。生產部署採用藍綠部署或金絲雀發布,降低風險。故障處理自動化,常見問題自動診斷和修復,減少人工介入。
智慧監控告警不僅要監控當前狀態,更要預測未來趨勢。使用機器學習模型進行異常檢測,識別異常交易模式和系統行為。建立多維度告警規則,結合技術指標和業務指標。告警分級處理,根據嚴重程度自動通知相應人員。實施告警收斂,避免告警風暴,聚焦根本原因。
持續效能優化是永無止境的追求。定期進行效能剖析,使用工具如 JProfiler、Perf、VTune 識別效能瓶頸。建立效能基準線,追蹤長期趨勢。A/B 測試新的優化方案,量化改進效果。容量規劃要有前瞻性,根據業務增長預測,提前半年進行擴容準備。
知識管理體系確保團隊能力的持續提升。建立完善的文件體系,包括架構文件、運維手冊、故障處理指南。定期進行技術分享,總結經驗教訓。建立故障覆盤機制,每次故障後進行根因分析,制定改進措施。培養全棧工程師,確保團隊成員理解系統全貌。
金融交易系統的設計是系統架構的巔峰挑戰,它要求我們在多個看似矛盾的目標間找到平衡。極致的效能要求與絕對的可靠性要求並存,嚴格的監管合規與快速的業務創新並重。通過今天的深入探討,我們理解了如何通過分階段演進、合理的技術選型、以及完善的運維體系來應對這些挑戰。
最關鍵的啟示是:沒有一步到位的完美架構,只有持續演進的系統。從簡單的單體架構開始,根據實際業務需求和技術瓶頸,逐步引入更複雜的技術。這種務實的方法不僅降低了風險,也確保了投資回報。
確定性優於平均效能:在金融交易中,延遲的可預測性比平均延遲更重要。寧可 P50 略高,也要確保 P99 穩定。
簡單可靠優於複雜高效:除非確實需要,否則選擇簡單成熟的方案。複雜性是可靠性的敵人。
數據不可變性原則:所有交易數據一旦產生就不可修改,只能新增。這確保了審計追蹤的完整性。
故障隔離設計:任何單一組件的故障都不應影響核心交易功能。使用艙壁模式隔離故障域。
監管合規內建:從設計開始就考慮合規要求,將監管規則編碼到系統中,而非事後補充。
針對今日探討的金融交易系統設計,建議可從以下關鍵字或概念深化研究與實踐,以擴展技術視野與解決方案能力:
硬體加速技術(FPGA/GPU/DPU):深入了解硬體加速在金融交易的應用,學習 HLS 開發、OpenCL 編程,掌握硬體與軟體協同設計的方法。
分散式共識協議(Raft/Paxos/PBFT):研究分散式系統的一致性保證機制,理解如何在網路分區情況下保證數據一致性,這對構建高可用交易系統至關重要。
監管科技(RegTech)與合規自動化:探索 AI 在監管合規的應用,了解 MiFID II、Basel III 等國際監管框架,掌握自動化報告生成和實時合規監控技術。
量子計算與後量子密碼學:關注量子計算對金融科技的影響,了解量子算法在投資組合優化的應用,學習後量子密碼學以應對未來的安全挑戰。
DeFi 協議與智慧合約:研究去中心化金融的核心協議,理解 AMM(自動做市商)機制,探索傳統金融與 DeFi 的融合可能性。
可根據自身興趣,針對上述關鍵字搜尋最新技術文章、專業書籍或參加線上課程,逐步累積專業知識和實踐經驗。
明天我們將進入另一個激動人心的領域——「IoT資料收集系統」。當數百萬個感測器如潮水般湧來的數據該如何處理?如何在邊緣端進行智慧運算?
如何確保從感測器到雲端的數據安全?IoT正在改變世界,而掌握 IoT 架構設計將是通往未來的關鍵技能。讓我們一起探索這個萬物互聯的新世界!


 iThome鐵人賽
iThome鐵人賽